
一、并查集(Disjoint Set Union,DSU)
1.引入
并查集(Disjoint Set Union,DSU)是一种用于处理不相交集合的合并和查询树形问题的数据结构,其主要有两种操作方式:
- 查找(Find):确定某个元素属于哪个集合(通常返回集合的“代表元”)。
- 合并(Union):将两个不同的集合合并为一个集合。
并查集广泛应用于连通性问题,如:
- 图论中的连通分量判断(Kruskal 算法求最小生成树)
- 动态连通性问题(网络连接、社交网络好友关系)
- 集合划分问题
- 最近公共祖先(LCA)的离线算法
我们来思考这样一个问题:
有 n 位魔法少女,编号从 1 到 n。初始时,大家互相都不认识(各自为阵)。接下来会依次发生 m 个事件,每个事件可能是以下两种之一:
- 成为朋友(op = 1):魔法少女 x 和 y 通过契约建立了直接的朋友关系。
- 询问是否同阵(op = 2):询问魔法少女 x 和 y 是否在同一个魔法阵中(即是否可以通过一系列朋友关系相连)。
对于每个询问,你需要输出 “Yes” 或 “No”。
第一行两个整数 n, m,表示魔法少女数量(1 ≤ n ≤ 10^5)和事件数量(1 ≤ m ≤ 2×10^5)。
接下来 m 行,每行三个整数 op, x, y,其中 op 为 1 或 2,x 和 y 为魔法少女的编号(1 ≤ x, y ≤ n)。
对于上面这个问题,我们可以把整个过程分为三步:
- 初始时,每个魔法少女独自为一个集合(魔法阵)。
- 当发生“成为朋友”事件时,将两个魔法少女所在的集合合并。
- 当发生“询问”事件时,判断两个魔法少女是否在同一集合(即根节点是否相同)。
2.基础并查集
下面给出用并查集解决这个问题的代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int parent[N];
void init(int n)
{
//初始化parent数组,没一个魔法少女默认只和自己是朋友
for (int i = 1; i <= n; ++i)
parent[i] = i;
}
int find(int x)
{
//查询第x位魔法少女是不是还是只和自己是朋友
while (x != parent[x])
{
x = parent[x];
}
return x;
}
void unite(int x, int y)
{
//将x和y变成朋友
int rx = find(x);
int ry = find(y);
if (rx != ry)
{
parent[ry] = rx;
}
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n, m;
cin >> n >> m;
init(n);
while (m--)
{
int op, x, y;
cin >> op >> x >> y;
if (op == 1)
{
unite(x, y);
}
else
{
if (find(x) == find(y))
cout << "Yes" << endl;
else
cout << "No" << endl;
}
}
}我们对于这一个样例进行分析:
输入:
5 6
1 1 2
1 2 3
2 1 3
2 3 4
1 4 5
2 4 5
输出:
Yes
No
Yes
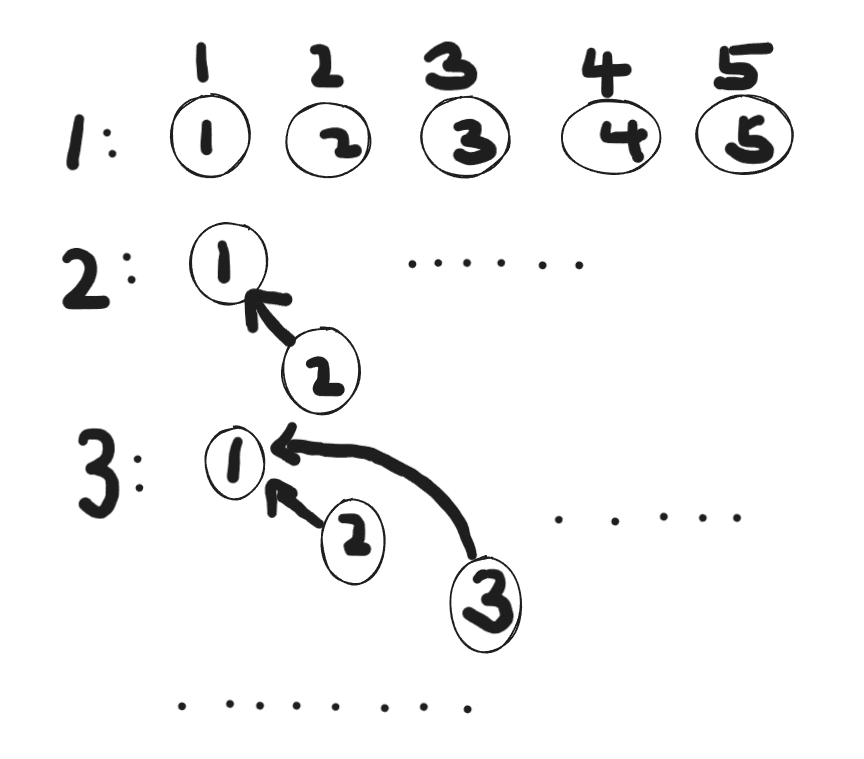
不难发现初始化之后1 1 2会是parent数组里的parent[2]=find(1)=1,同理,1 2 3也会把parent[3] = find(2)=1,此时查询1和3的关系,调用if判断find(1)和find(3)会发现都指向了1,此时就代表是朋友,不同则代表查询这一刻还不是朋友,没有例外。
最后对于这一组样例parent数组会变为:
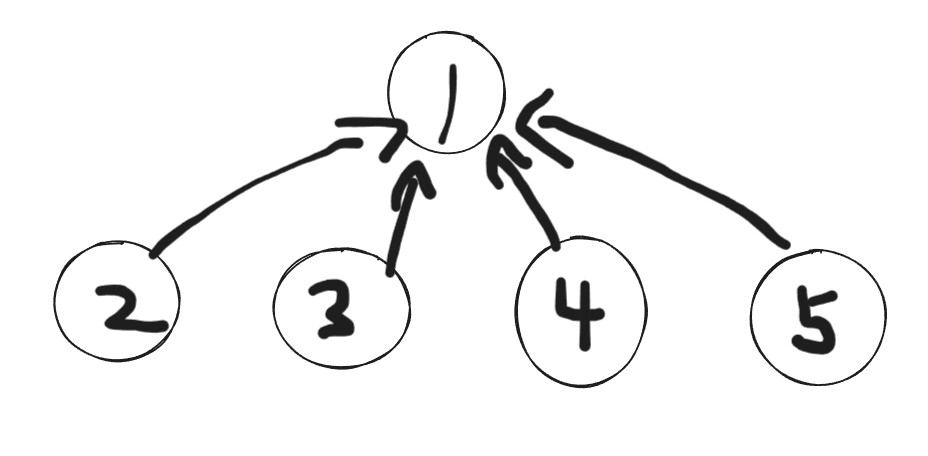
其中parent数组的值全指向parent[1]=1。
显然代码是正确且合理的,不过,能不能再优化以下呢?如果我们的样例变成里面合并操作变为1和2,3和1,4和3,5和4时我们的parent数组会变成什么呢?下面给出parent数组最后的数值:
parent[1]=3,parent[2]=1,parent[3]=4,parent[4]=5,parent[5]=5。这时候代表着每一位魔法少女和彼此都是朋友,这时我们如果查询1和2是否为朋友find函数会一直调用到x=5时才会返回值,这种极端条件下树形结构退化为线性,此时若n和m都很大,查询都很极端,时间复杂度将会变为O(nm),显然超时。
3.优化并查集
我们的思路是对的,但是必须要优化。优化从哪里入手呢?通常,我们可以进行路径压缩,下面先给出路径压缩后对应的find函数代码:
int find(int x)
{
//查询第x位魔法少女是不是还是只和自己是朋友
if (parent[x] != x)
{
parent[x] = find(parent[x]);
}
return parent[x];
}读者不妨自己对以下样例进行模拟:
输入:
5 6
1 1 2
1 3 1
1 4 3
1 5 4
2 2 5
2 1 5
输出:
Yes
Yes
我们在find(x)函数中直接将parent[x]进行修改,使得第一次后每一次查过和parent[x]有朋友关系的所有节点都会指向最终共同的根节点,以后仅需一步就能直接查询根节点。这样的优化已经足够了,对于样例第一次的查询时依旧是parent[1]=3,parent[2]=1,parent[3]=4,parent[4]=5,parent[5]=5,但是当第二次查询时parent数组变为parent[1]=5,parent[2]=5,parent[3]=5,parent[4]=5,parent[5]=5,一步即到位,读者可以手写模拟一遍变换流程。这样就算是最极端的情况,除了第一次查询我们需要从尾到头,其他次查询复杂度均为O(1)。
那么还可以不可以在此提升呢?当然可以,以下内容读者可以了解,优化程度远不及路径压缩效率,结合使用对于时间复杂度的优化也十分有限,因为路径压缩效率已经足够高了。我们从find函数进行了压缩,那么我们是不是也可以在unite函数运行时就进行压缩操作呢?当然可以,以下这种压缩方式叫做按秩合并,下面给出修改优化后的unite函数:
int rank_[N]; // 记录树的高度(秩),注意避开关键字 rank
void init(int n) {
for (int i = 1; i <= n; i++) {
parent[i] = i;
rank_[i] = 0; // 初始秩为0
}
}
void unite(int x, int y) {
int rx = find(x);
int ry = find(y);
if (rx == ry) return;
// 按秩合并:将秩小的树合并到秩大的树
if (rank_[rx] < rank_[ry]) {
parent[rx] = ry;
} else if (rank_[rootX] > rank_[rootY]) {
parent[ry] = rx;
} else {
// 秩相等,将 rootY 合并到 rootX,并增加 rootX 的秩
parent[ry] = rx;
rank_[rx]++;
}
}unite函数这样修改后到查询之前parent数组已经全部为1了,路径压缩有无在这个样例中无提升。对于提交题目时的复杂样例组成来说,将路径压缩和按秩合并结合将会达到并查集的理论最优时间复杂度O(α(n)),其中α(n)是反阿克曼函数(Inverse Ackermann Function),阿克曼函数本身是一个“怪兽级”的函数,增长速度极快,快到 就已经是一个天文数字 。因此,它的反函数 的增长速度就极慢。
